同じ日付の項目が複数並んでいる場合がありますが、必ずしも間違いではありません。
Word 2007 で文章に脚注を入れるには、リボンの「参考資料」タブを選び、「脚注の挿入」コマンドを選びます。この「参考資料」というタブの名前は意味がわかりません。このタブには目次・脚注・引用文献・図表番号・索引・引用文など、よそから番号や文章を取得して挿入する操作が並んでいます。こういうのは、日本語では「参照」、英語では「reference」と言います。実際、英語版の Word 2007 ではタブの名前は「References」になっています (英語版のヘルプ)。さらに、「reference」という英単語には「参考資料」という意味もあります。……つまり、「参考資料」は「References」の誤訳で、正しくは「参照」とするべきです。
Word は大きなソフトウェアなので、細かいところに誤訳があっても仕方がないと思いますが、こんな目立つ場所に誤訳があっては、少しでも日本語訳の確認をしたのかどうか疑いたくなります。 Word 2007 を含む Office 2007 のメニュー構造の大変更は、基本的には悪くないと思っていますが、それは変更後が良くできている場合の話です。僕はこの誤訳のせいで脚注の挿入の仕方がヘルプを見るまでわかりませんでした。誤訳のせいで機能のありかがわからないのでは、新しいユーザーインターフェースが良いか悪いか以前の問題です。
僕は一人で使う Windows PC であっても、普段は制限ユーザーで使っていて、特権が必要なときだけ「別のユーザーとして実行」を使うか管理者でログオンし直しています。こうすることで、システム全体に影響が及ぶような操作を意図せず実行してしまう危険が減ります。ただし、逆に特権が必要になるたびに管理者ユーザーのパスワードを入力する必要があります。
これまでそういうものだと思って使っていたので、特に不満はないのですが、 Windows Vista ではそんな面倒なことをしなくても、普段から管理者ユーザーでログオンして使っていればよいのではないかと思い当たりました。
Windows Vista のユーザーアカウント制御 (UAC) の動作について、 Windows Vista User Account Control step by step guide (Microsoft TechNet) と The Windows Vista and Windows Server 2008 developer story: Windows Vista application development requirements for User Account Control (UAC) (MSDN Library) を斜め読みしました。 UAC が有効の場合、管理者ユーザーがログオンすると、 Admin Approval Mode という状態になります。 Admin Approval Mode では、プロセスは標準ユーザー (Windows XP 以前では「制限ユーザー」と呼ばれていた) と同じ権限でしか動きません。 Admin Approval Mode で管理者権限を要求する実行ファイルを実行しようとすると、「実行ファイルが管理者権限を要求しているが、認めて大丈夫か」と問う consent prompt ダイアログボックスが表示されます。ユーザーが consent prompt を承認して初めてプロセスに管理者権限が与えられます。
ということは、管理者でログオンしたとしても、管理者権限を必要とする操作を意図せず実行してしまうのは防げているように思います。試してみないで、調べたことを書いているだけですが、これで合っているなら、個人で使う Windows システムにおけるセキュリティー上望ましいユーザーアカウントの管理方法は Vista で大きく変わることになるのではないかと思います。でも、「XP 以前では制限ユーザーを常用するべきだが、 Vista では管理者ユーザーを常用しても大丈夫」なんて解説は読んだことがないので、何か僕が勘違いしているのかもしれません。
7 年前の 2000 年 9 月にテレビのニュース番組の中でキャスターが言った言葉がいまだに忘れられません (言い回しは違うかもしれません)。
介護保険制度が始まって 5 ヶ月がたち、 6 ヶ月目に入りました。半年目ですね。
趣味が悪くてすみませんが、僕が今までに観たニュース番組の間違いの中で最も面白かったものです。
Yahoo! カテゴリでは、 Yahoo! が特に優れていると認めるウェブサイト (クールサイト) にサングラスのアイコンを付けて表示しています。参考: Yahoo! カテゴリのアイコンの説明。
Yahoo! はクールサイトだそうですが、 Google はクールサイトではないそうです。 Yahoo! は良いサイトだと思いますが、自画自賛……?
ちなみに、 日本以外の各国の Yahoo! もクールサイトでないらしいです。同胞を貶めて自分だけのし上がろうとしている……わけではなくて、これはたぶん日本語話者にとって有用かどうかでクールサイトの認定を決めているからでしょう。
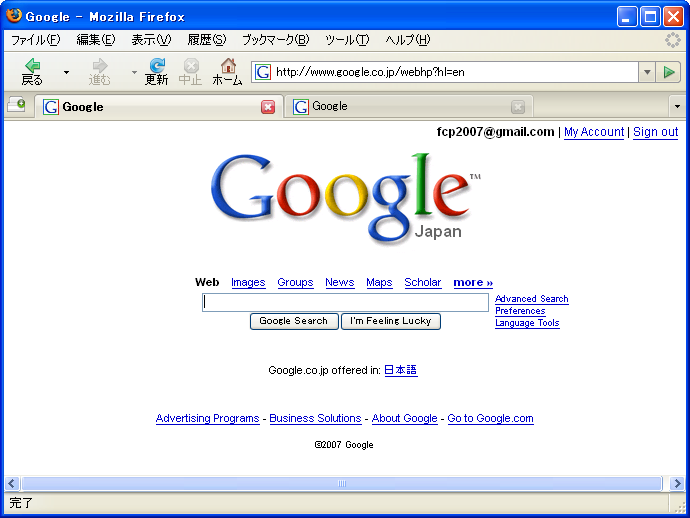
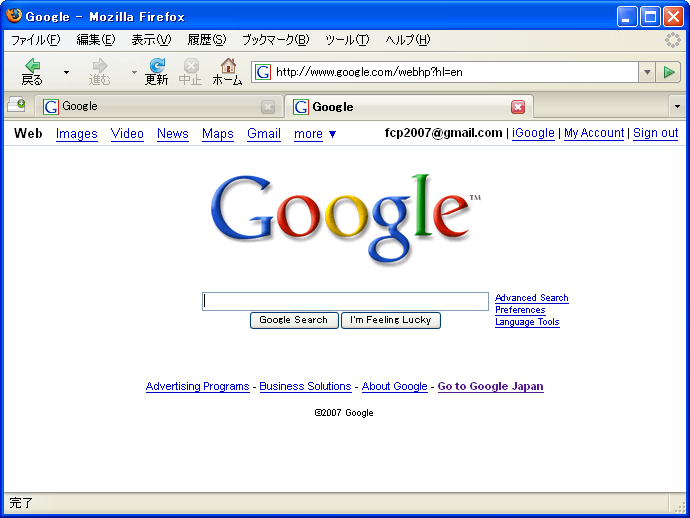
google.co.jp の英語版と google.com の英語版とは少し見かけが違います。 google.co.jp 英語版ではロゴが「Google Japan」になるのは知っていたのですが、「Web Image Video News Maps Gmail more」というメニューの位置も違うことに気付きました。
また、メニューの中の「more」のリンクの動きも違います。 google.co.jp では「more」は More Google products へのリンクになっているので、検索結果の画面から「more」を選ぶと検索語が消えてしまいます。一方、 google.com では「more」はスクリプトで動くようになっていて、検索結果の画面から more の中の Blog Search 等のリンクを選ぶと同じ検索語で自動的に検索してくれるようになっています。 more の中の検索を使う場合には google.com の方が少し便利です。
google.com の方が新しいということでしょうか。そうだとすると、そのうち google.co.jp 英語版や日本語版でも google.com 英語版のようなメニューが使われるようになるのでしょう。
google.co.jp 英語版:
google.com 英語版:
発言のリストとして僕が当サイト以外で行った発言へのリンクを載せていますが、一部の発言について本文も載せてみました。
下の二つは最初 9 月 8 日と書いていましたが、 9 月 9 日の間違いでした。日付を間違えるのはしょっちゅうです。
「さっきの話はネタだから本気にするなよ」のように「ネタ」を「冗談」の意味で使う用法は、どうも好きではありません。この用法はここ数年のうちに生まれたのではないかと思っていますが、真偽を簡単に確かめる方法が思いつかないので、本当のところはよくわかりません。「年金問題をネタにした漫才」のような用法から転じて冗談そのものを指すようになったのではないかと予想しています。
ところで、僕自身、 2 月 11 日には「一発ネタ」という言葉を使っています。これは「ネタ」を「冗談」の意味で使う用法に非常に近そうです。好きでないとか言っておいて、別の場所では自分でまったく気にせずに使っているのだから、矛盾していますね……。まあ、僕の言葉の好き嫌いなんてその程度のものだということでしょう。
Perl では原則として文字列を UTF-8 で符号化して記憶します。このため、 Perl で文字列を扱う場合の原則的な手順は、読み込みの時に UTF-8 に変換し、処理はすべて UTF-8 で行い、出力の時に所望の符号化方式に変換するというものになります。ただし、あくまでもこれが原則というだけで、最初から最後まで US-ASCII の文字列だけで済む場合などには変換の処理を省略する場合もあります。
さて、 Perl の encoding プラグマを使えば、スクリプトをシフト JIS コードなど好きな文字コードで書くことができます。しかし、文字コードの変換のための Encode モジュールを同じスクリプト内で使う場合、 encoding プラグマを使うのは避けた方が無難のようです (少なくとも僕の理解度では)。スクリプト中に US-ASCII 以外の文字を書きたい場合、 UTF-8 で書いて utf8 プラグマを使う方が簡単です。
例えば、
use Encode ();
my $s = Encode::decode('SHIFT_JIS', "\x93\xFA\x96\x7B\x8C\xEA");
printf "%vX\n", $s;
というコードを実行すると、シフト JIS コードで「93 FA 96 7B 8C EA」は「日本語」という文字列であって、この 3 個の漢字の Unicode でのコードポイントは U+65E5、 U+672C、 U+8A9E なので、
65E5.672C.8A9E
と出力されます。このプログラムの先頭に use utf8; という行を加えても動作は変わりません。しかし、 use utf8; の代わりに use encoding 'SHIFT_JIS'; や use encoding 'UTF-8'; と書くと、
Wide character in subroutine entry at C:/Perl/lib/Encode.pm line 166.
といって怒られます。
エラーになる理由は、 encoding プラグマを使うと "\x93\xFA\x96\x7B\x8C\xEA" という文字列がバイト列から Unicode 文字列に自動的に変換されてしまうからです。後日、もう少し詳しく調べて書こうと思います。